
為什麼這三層不能混為一談,混淆它們又如何讓 LLM 架構變得脆弱。
Taxonomy、Ontology、Knowledge Graph,這三個詞常常出現在同一句話裡,也常常被當成差不多的意思在用。
但它們不是。
只要開發團隊開始模糊了這三個概念,架構決策就會跟著出問題。開發者會:
- 期待某一層做另一層該做的事,
- 高估 Retrieval 能修補多少問題,又
- 低估語意的模糊性會悄悄地滲進模型,改變模型的行為。
小規模 Demo 的時候,這些問題很容易掩蓋過去。一旦進入正式的 LLM 或 Agentic AI 系統,代價就會很高。
看起來像是鄰居,但住的不是同一棟樓
這種混淆我也曾經犯過,情有可原。(原諒自己的無知)
Taxonomy、Ontology 和 Knowledge Graph 都在處理「如何組織知識」,也都能幫助人和系統找到、整理和推理資訊。三者甚至可以共存於同一個平台上。
但它們回答的是不同的問題:
- Taxonomy:東西怎麼被歸類 (how things are grouped)
- Ontology:東西代表什麼意思 (what things mean)
- Knowledge Graph:真實事物之間怎麼連結 (how real things are connected)
不要以為是學術上的咬文嚼字,其實這是真實的系統設計問題。
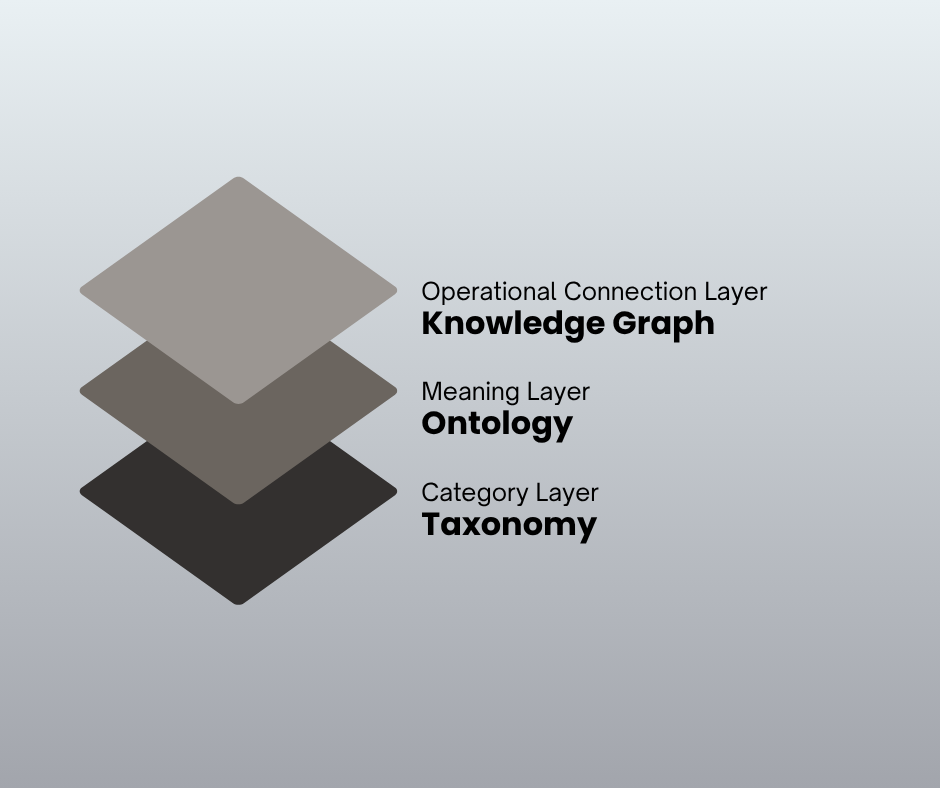
Taxonomy 是分類層
Taxonomy 是三者中最輕量的結構。
它的目的是把東西放進「更大」或「更小」的桶子裡,提供受控的分類、一致的標籤、更清楚的導覽。
Taxonomy 很好用,尤其是當要回答這些問題時:
- 這個東西應該歸在哪裡?
- 它的上層類別是什麼?
- 我們應該統一用哪個標籤?
這就是為什麼 Taxonomy 很適合做導覽、標籤、產品目錄、文件分群,以及 Faceted Search。
但 Taxonomy 有它的極限。
它可以告訴你一個東西屬於哪個類別,卻通常無法說清楚概念之間更豐富的語意、跨領域的有效關係,或定義正確解讀的條件限制。
簡單說:Taxonomy 擅長處理層級關係,但光靠它不足以控制語意。
Ontology 是語意層
Ontology 走得更深。
它定義一個領域裡有哪些概念、概念之間的關係,以及什麼才算合法的解讀。
如果說 Taxonomy 是在整理標籤,那麼 Ontology 就是在穩住意義。
當多個團隊、系統或模型需要共用同一套概念框架時,Ontology 就顯得特別重要。一旦大家開始用同一個詞指稱不同的事物,或用不同的詞指稱同一件事物,系統運作的品質就會快速下滑、Retrieval 開始出錯,分析結果變得不一致,模型輸出開始漂移,Agent 開始看起來像是理解了業務邏輯,但其實正默默地違反它。
Ontology 透過讓語意結構化來減少這類失敗。
它帶來的是:
- 穩定的領域定義
- 有意義的關係描述
- 具備條件限制的解讀能力
- 更清楚的可解釋性
- 人類語言與機器處理之間更緊密的對齊
這也是為什麼 LLM 進入正式工作流程之後,Ontology 的價值反而更高。
LLM 非常擅長產出流暢的文字,但它不會自動在跨團隊、跨系統、跨決策的情境下維護共享語意。
所以我越來越把 Ontology 看作 AI 的控制層,而不只是一種老派的知識建模練習,並且也在公司的業務中實踐。
Knowledge Graph 是運作連結層
Knowledge Graph 是這些想法真正成為可落實資料的地方。
在這一層,實體、關係與情境被實際連結起來,可以被查詢並重複使用。
一個好記的分法:
- Taxonomy 整理類別
- Ontology 定義意義
- Knowledge Graph 用這些結構把真實的實例連起來
這就是為什麼 Knowledge Graph 在需要跨越資訊孤島進行推理的環境中如此重要。
它把關係當作第一層結構保存,而不是讓它們消失在一堆資料表、文件、應用程式和各自為政的工作流程之間。
很多重要的業務問題,本質上不是「查記錄」的問題,而是「找關係」的問題。比如:
- 哪個批次的產出和哪個異常事件有關?
- 哪個來源支撐哪個論點?
- 哪些團隊用了「意思重疊卻不同名稱」的詞?
- 哪個下游工作流程依賴這個實體、事件或規則?
這些都是 Graph 形狀的問題。
Graph 的價值不在於它很流行,而在於有些問題本質上就是關係問題。
為什麼 LLM 時代讓這件事更重要
AI 專案裡有個常見的模式:直接跳到生成。
團隊收集文件、建 Retrieval、寫 Prompt、開始測試輸出。對輕量的應用場景來說,這樣可能夠用。
但一旦系統需要可靠、可解釋、可重複使用,或者具備 Agentic 能力,底層的語意基礎就變得非常關鍵。
- Taxonomy 層不紮實,Retrieval 就會充滿雜訊
- Ontology 層不紮實,術語開始漂移,推理變得不穩定
- Graph 層不紮實,模型就失去了跨系統的運作情境
這就是為什麼很多系統 Demo 看起來很厲害,進了正式環境運行卻很脆弱。
模型被要求補償那些本來應該在結構層面就處理好的模糊性。這種狀況我會說:模型被污染了。
所以問題不是:「Taxonomy、Ontology、Knowledge Graph,哪個比較好?」更好的問題是:
哪一層在解決哪個問題?
這一個問題,通常就能讓整個架構討論清晰很多。
一個實用的判斷原則
如果主要問題是分類、導覽或受控標籤,從 Taxonomy 開始。
如果主要問題是語意一致性、共享意義、有效關係或可解釋的解讀,加上 Ontology。
如果主要問題是跨實體、跨系統的運作情境連結,你可能需要 Graph 層。
在正式的 AI 系統,尤其是企業級和 Agentic 系統,你通常三個都會用到。不是因為複雜性本身值得追求,而是因為問題本身就是分層的。
一套可復用的架構
我越來越常用的架構分法是:
- Taxonomy:負責結構
- Ontology:負責控制
- Knowledge Graph:負責運作
- LLM:負責語言與彈性推理
這個框架幫助避免一個常見的錯誤:強迫某個元件去補償另一個元件的缺席。這往往才是讓系統變脆弱的真正原因。
系統失敗,通常不是因為模型沒用,而是因為語意層根本沒建好。
結語
系統越來越 Agentic,我們對語意模糊的容忍度越來越低。一個在模糊的分類上、薄弱的語意裡、斷裂的情境中運作的 Agent,不只是受限而已,它是難以預測的、不受控的。
因此,把 Taxonomy、Ontology、Knowledge Graph 說清楚,不是理論上的整理工作,而是打造可信賴 AI 的基礎之一。



